













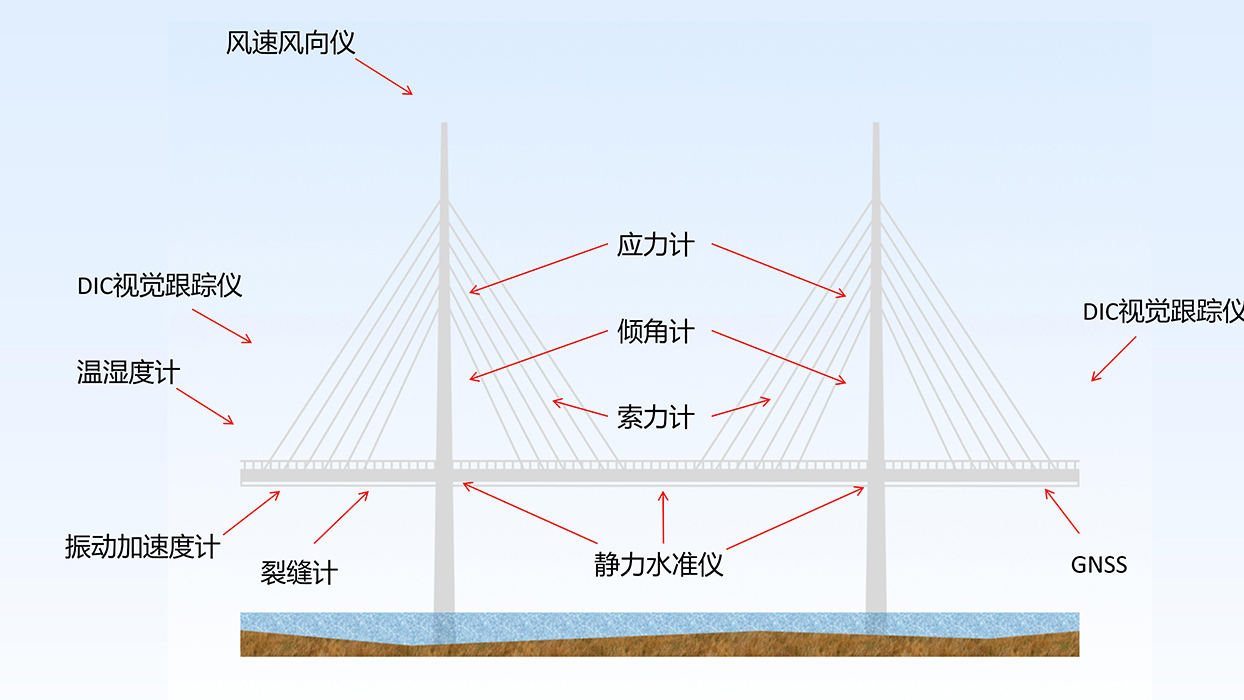
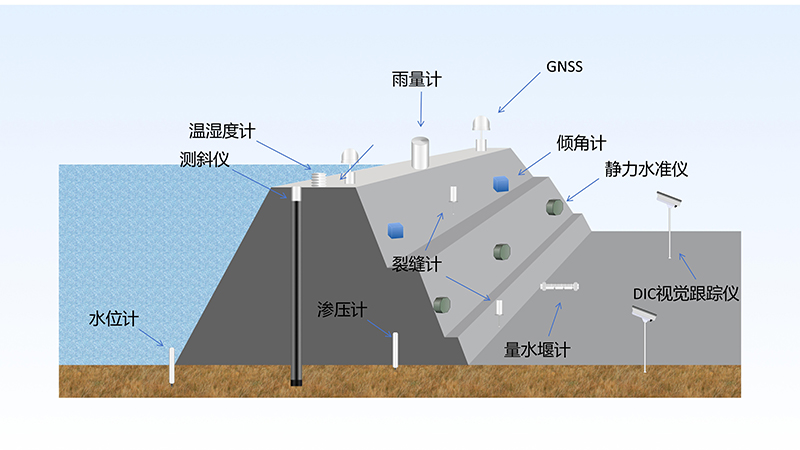
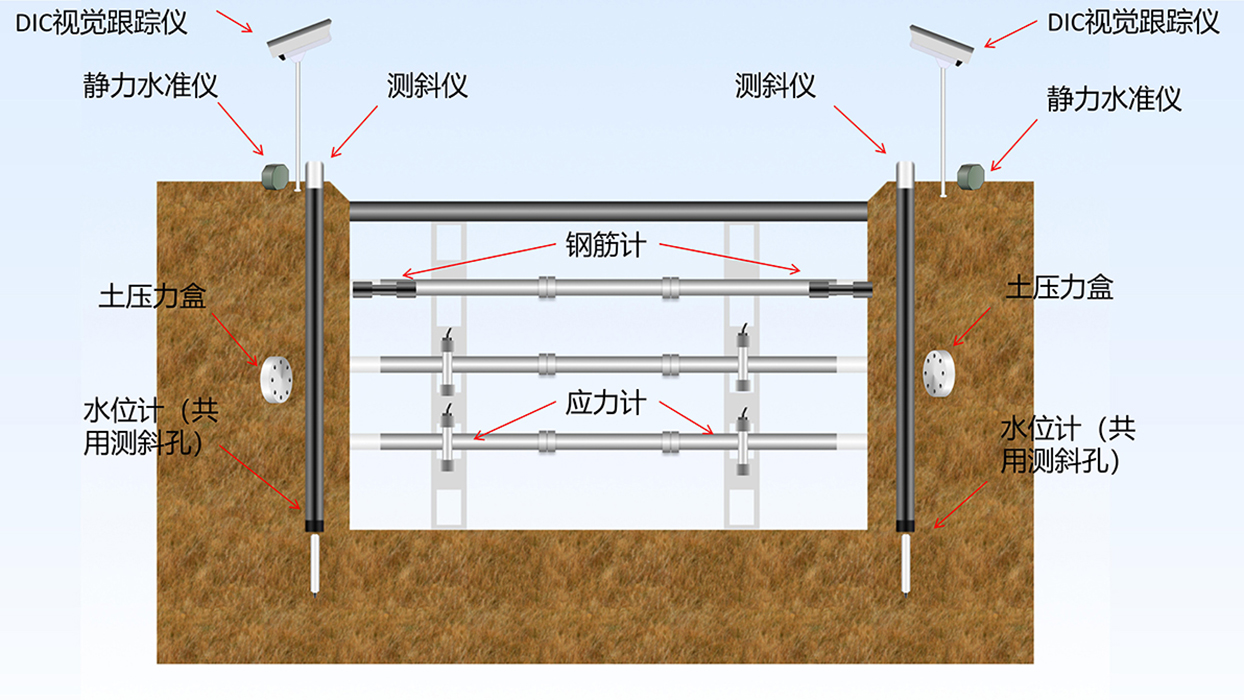
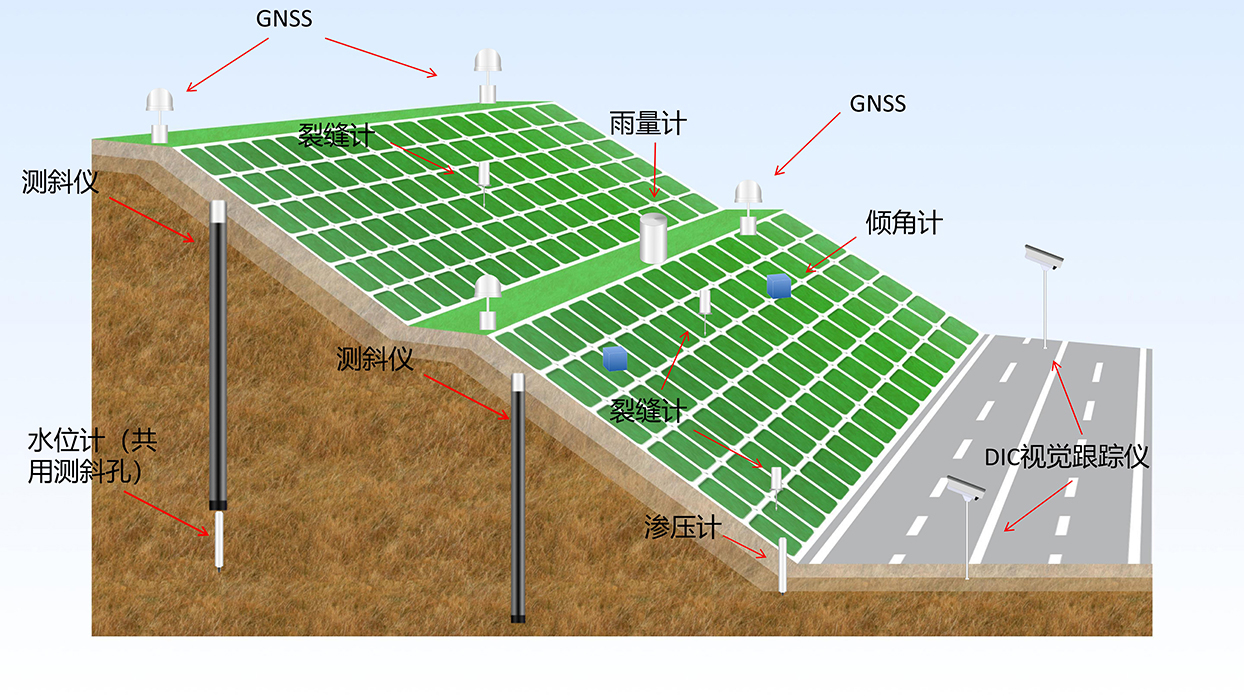

导读
近期,海塞姆科技首席科学家北京航空航天大学潘兵教授课题组在Experimental Mechanics上发文“User-Independent, Accurate and Pixel-Wise DIC Measurements with a Task-Optimized Neural Network”。论文介绍了一种新的基于任务优化神经的深度学习数字图像相关方法(Digital image correlation, DIC)—RAFT-DIC,通过针对性地改进深度学习DIC框架并开发新的数据集生成方法对模型进行训练,RAFT-DIC可实现全自动、逐像素、高精度的位移场测量。与现有深度学习DIC方法相比,RAFT-DIC的亚像素位移测量精度约高出一个数量级,且具有更强的跨数据集泛化性能和实用性。
文章信息:Pan B, Liu Y. User-Independent, Accurate and Pixel-Wise DIC Measurements with a Task-Optimized Neural Network[J]. Experimental Mechanics, 2024: 1-15.
链接:https://link.springer.com/article/10.1007/s11340-024-01088-4

研究背景
数字图像相关方法因其非接触全场测量、使用简单便捷、适用范围广泛等优点,已成为实验力学领域主流的位移和变形测量技术, 被广泛应用于不同科学和工程领域。尽管基于图像子区的局部DIC算法(常规DIC)在测量精准度、计算效率和鲁棒性方面取得了重大进展,并在商业软件中普遍使用,但仍存在以下两个不足:
1) 常规DIC计算要求用户明确输入关键计算参数(图像子区大小、形函数阶数等)以进行后续的相关计算,无法实现使用者独立的全自动测量;
2) 常规DIC计算是在参考图像上指定均匀分布的计算点(相邻点之间的距离是使用者指定的计算步长)上进行的,因此输出的是离散计算结果,无法实现逐像素稠密位移场测量。
为了解决常规DIC的这些固有局限,深度学习是一种可能的解决方案。自 2021 年深度学习被首次引入 DIC以来,各种基于深度学习的 DIC 方法已经证明了神经网络在图像变形测量方面的潜力和优势。与常规DIC相比,深度学习DIC可以在网络训练后以端到端的方式输出稠密位移场,且该过程无需使用者人为选择计算参数。尽管已有很多学者尝试将深度学习引入DIC,但现有深度学习DIC的亚像素位移测量精准度与常规DIC相比没有明显优势,特别是对于(平移、转动、拉伸和剪切或其组合等)低频位移场。此外,现有深度学习DIC的泛化能力不足,导致其在实际实验图片中的表现不如测试数据集。
技术路线
在网络框架方面,本文借鉴了深度学习光流估计领域研究进展,并充分利用了DIC测量的先验信息(计算像素之间的相似度及迭代更新位移场),从根本上优化了网络框架。在光流估计领域中,递归全对场变换框架(Recurrent All-Pairs Field Transforms, RAFT)框架在提出时达到了最高的光流估计精度(误差约为3个像素),并成为深度学习光流估计的第三代标准框架。尽管RAFT在光流估计领域表现出优异的性能,但其亚像素精度远远达不到DIC测量需求,因此RAFT框架并不适合直接应用于DIC测量。
为此,本文对原始 RAFT 框架进行了针对性的修改以提高其测量性能。修改后的位移估计框架称为RAFT-DIC(主要模块如图1所示),其主要整体框架由三个模块组成:1)编码器模块:提取参考散斑图像和变形图像的特征信息;2)4D相关层:通过构建参考图像特征和变形图像的特征向量所有对之间的4D 相关层,计算出参考图像和变形图像的相似性;3)迭代更新运算模块:使用基于卷积神经网络的迭代更新运算模块更新RAFT-DIC估计的位移场。

图1. RAFT-DIC框架的主要模块:1) 输出全分辨率特征的特征编码器和上下文编码器;2) 以两个尺度(1和1/2)池化的4D相关层构建的多尺度相关金字塔,3) 更新更新算子,用于更新和细化位移场。
RAFT-DIC对原始 RAFT 框架在两个方面做了针对性的修改:首先,去除了编码模块中所有的下采样操作,从而使模块感知更多的空间信息,大大提高了位移估计精度;其次,4D相关层的金字塔层数减少到两个,因此网络可以更高效地注重小位移精度。
在训练数据集方面,本文还开发了随机散斑图像和位移场数据集生成技术。通过充分考虑真实测量场景的因素(光照变化、散焦、相机放大倍率等),建立了分布广泛的散斑图像数据集(图2)。

图2. 合成的散斑数据集图像示例
此外本文提出一种无模型位移场数据集生成方法,将随机自然影像的灰度分布通过灰度归一化、随机模糊、随机放缩一系列操作转化为位移场分布(图3)。与现有的使用特定数学模型的位移场生成技术相比,位移场数据集的多样性和复杂性有所提高。基于所建立的散斑图像和位移场数据集生成技术,构建了一个分布广泛、鲁棒性强的数据集,极大地提高了RAFT-DIC的泛化性能。

图3. (a) 基于随机自然图像的位移场生成流程,(b) 随机自然图像样本以及相应的生成位移场。
实验结果
为验证RAFT-DIC方法相对于现有的基于一阶和二阶形函数的常规DIC (采用当前最先进的IC-GN算法) 和不同深度学习DIC (StrainNet-f、DisplacementNet和原始RAFT ) 的亚像素位移测量精准度,首先在图4的数值模拟图片中进行了测试,不同方法的实验结果如图5所示。实验结果表明,所提出的RAFT-DIC的精准度比其它方法高出约一个数量级。

图4. (a) 参考散斑图像和 (b) 施加的正弦位移场
图5. 使用一阶 DIC(图像子区大小21×21 像素,一阶形函数)、二阶 DIC(图像子区大小 : 21*21 像素)、StrainNet-f、DisplacementNet、原始 RAFT 和RAFT-DIC测量的 u 位移(左)和误差图(右)的比较。
为了进一步验证RAFT-DIC在真实实验图像中的性能,在橡胶试样三点弯曲试验和DIC challenge中的单向拉伸实验上进行了进一步测试。实验结果进一步证明了RAFT-DIC具有较强的跨数据集泛化性能和实用性。

图6. (a) 参考图像和 (b) 三点弯曲实验中的变形图像
图7. 标准 DIC、RAFT-DIC、StrainNet-f、DisplacementNet 和原始 RAFT 计算的 u 和 v 位移场

图8. (a) 单轴拉伸试验的参考图像和变形图像,(b) 常规 DIC(图像子区大小: 21 × 21 像素,计算步长 : 3 像素)、RAFT-DIC、StrainNet-f、DisplacementNet 和原始 RAFT 对应的 u 和 v 位移场
总结与展望
本文提出一种采用任务优化神经网络框架的深度学习DIC方法—RAFT-DIC,该方法可在无用户输入的情况下,以端到端的方式实现精准和像素级稠密的位移场测量。仿真实验和真实实验结果表明,RAFT-DIC在测量精准度和跨数据集泛化能力方面均优于现有的深度学习DIC方法。与常规DIC相比,RAFT-DIC不仅能输出逐像素的密集位移,无需手动选择关键计算参数,在具有复杂变形图像的位移测量上具有明显更高的精准度,对于简单变形图像则可获得与常规DIC相当的位移测量精准度。未来,研究人员将进一步提高RAFT-DIC的实用性,例如与其它神经网络结合拓展其位移测量范围,以及实现基于Raft-DIC的全自动、精准和稠密的3D-DIC测量,该先进算法将应用在海塞姆科技的新版软件中。




